
Squeeze #3: Slurm for Distributed Training.
From training one to 100s of GPUs without blowing your mind!

General idea of the Slurm is, when you try to use multi-gpu/node setups slurm does all the scheduling (aka resource allocation) and eventually you can run your scripts in each machine. at ease.
This is the third blog post for the Squeeze series, it's just all about squeezing every last FLOP from our GPUs
1. Distributed Training in Jupyter Notebooks
2. Pytorch Hooks
3. Slurm for Distributed Training (you're here)

And the most beautiful thing is distributed training frameworks are fully integrated with slurm; accelerate, deepspeed, torchrun, and many more…
You would also consider kubernetes for this. But as Stas Bekman stated in this tweet. It's painful and high learning curve road.

In this post, we're only talking about research and training language (or deep learning) model context, not about inference.
Because k8s is a powerful tool in terms of distributed inference and autoscaling. Especially with the llm-d framework. Fully inteqgrated LLM Inference framework into k8s with support of vLLM.

Anyway let's get back to the Slurm.
Engineers who developed slurm probably spent a lot of time brainstorming about the best developer experience for researchers. :)
It's really simple to use.
Whatever you can do it in your machine, you can do it in slurm too. It's a UNIX based environment that even you can activate the same virtual environment, you can use your shared storage, or get access to the other nodes (if it's allocated for your job.)
And if you're running a job in multi-gpu and several node systems; it's ok. But how about 1000s of nodes each consist of 8 gpus. that's gonna be whole different story. And slurm comes to your help, and remembers the thousands of IPs in some database for you.
Which is awesome, isn't it? 🎸

There are a lot of HPC (High Performance Computing) labs all around the world that uses Slurm systems.
These are examples:
Carina supercomputer (by Stanford Research Computing)
MareNostrum supercomputer (by Barcelona Supercomputing Center, BSC)
Lumi supercomputer (by EuroHPC Joint Undertaking)
Jupiter supercomputer (by Jülich Supercomputing Centre)
So we can say Slurm is the powerhouse backend of all these supercomputers!
And when you run sbatch with a slurm file, it schedules a job for you. Whenever requested resources are free, your job will be executed right away. And there's no possibility of interruption of your job!
The communication between the nodes are like this. All nodes are connected to each other, and communicates throughout the batches of training.
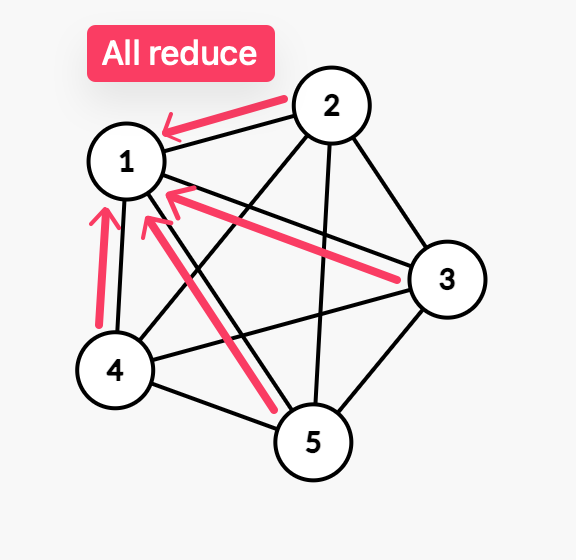
A lot of operations happens when you use distributed training. Shards all-reduced, all-gather, update and broadcasting it.
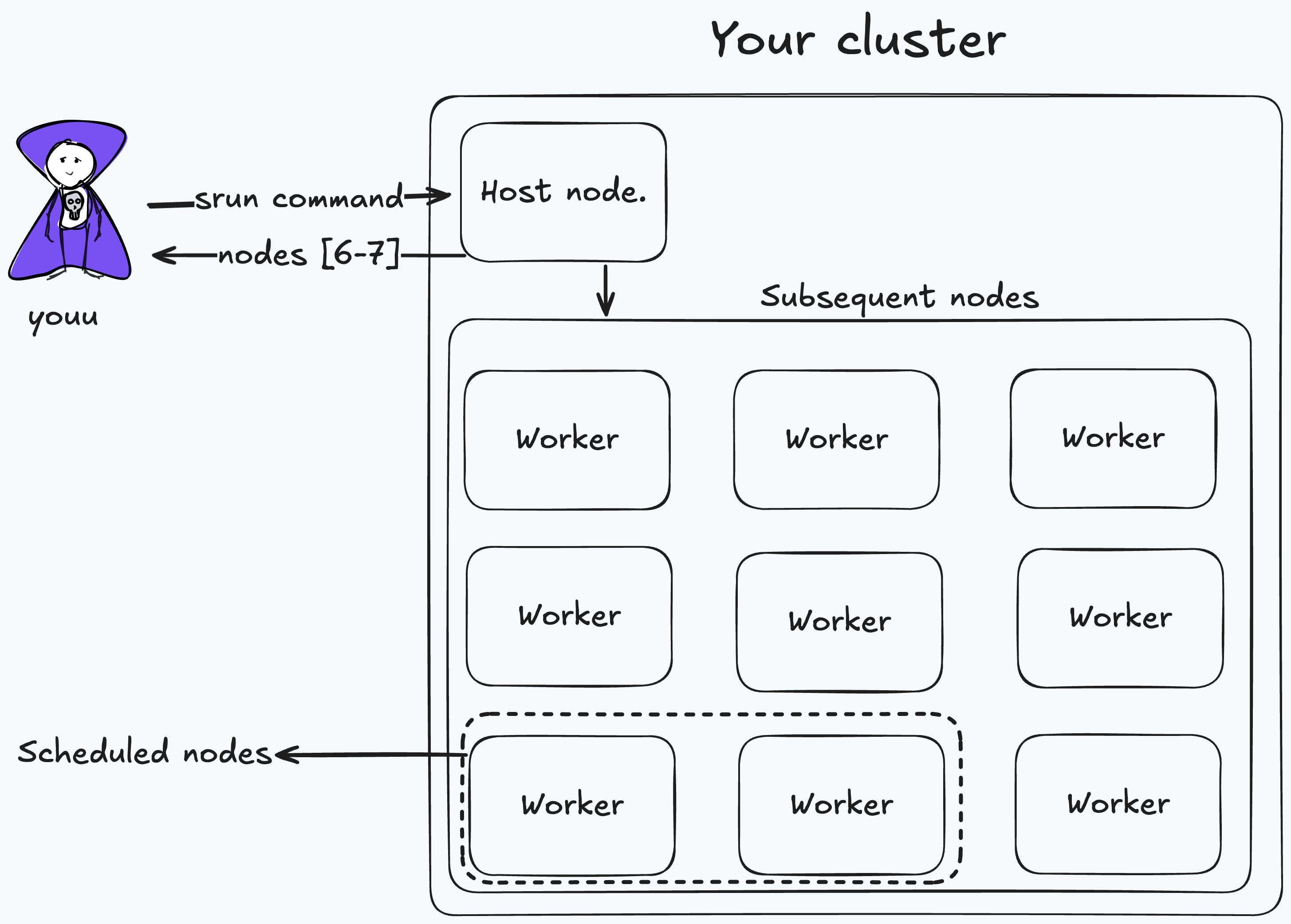
You can also be able to connect to a node(s) via srun command with —pty flag. It returns the interactive terminal to your current terminal.
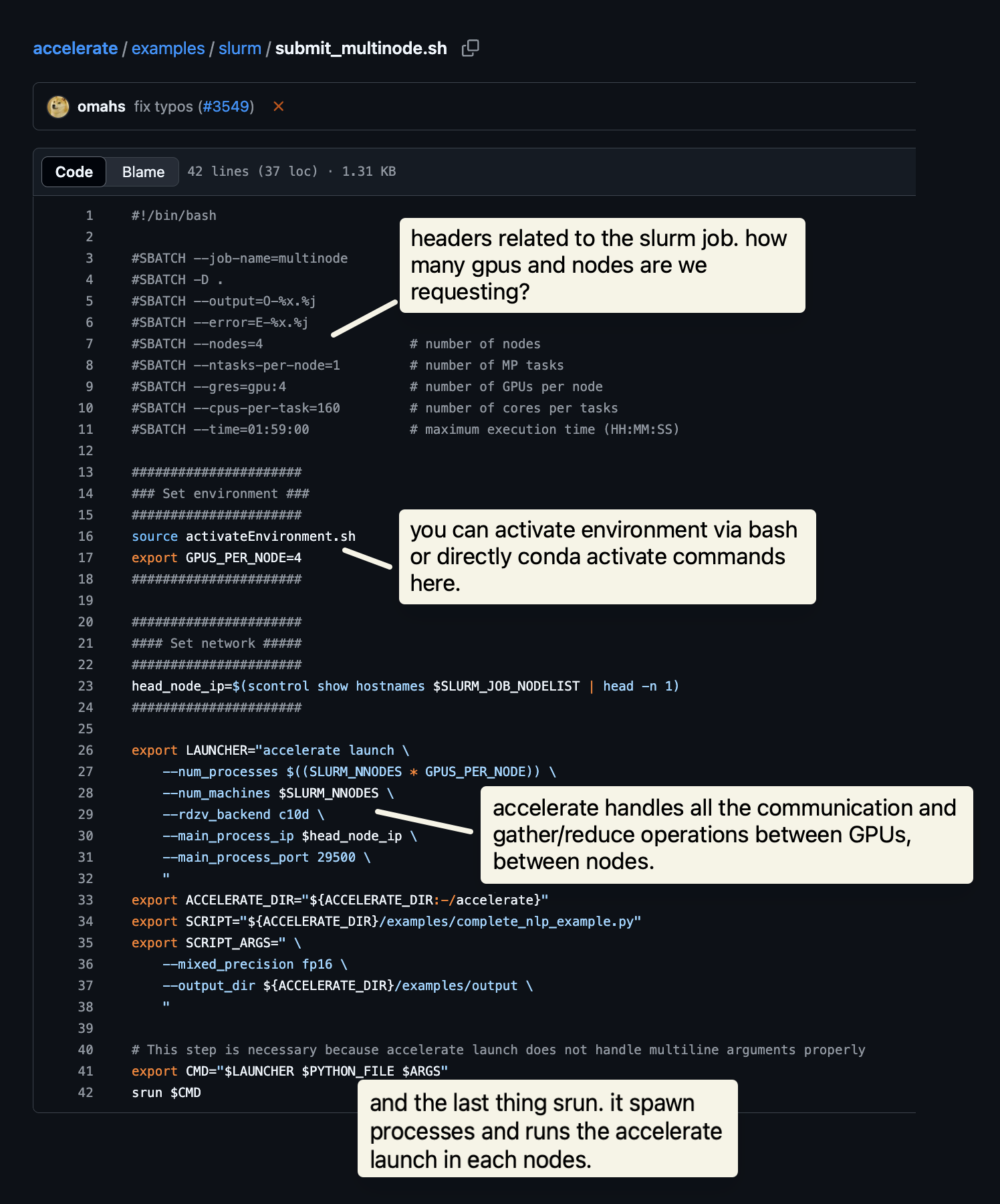
Check it out the below image for the anatomy of a SLURM file.
Fun fact: Slurm is %100 free and you need to deploy, configure, and customize it yourself! Highly recommended by experts like
, Stas Bekman, and prob. many more people!All credit goes to Zach Mueller!
To become up-to-date with the latest distributed training concepts. Use the following button to get Zach's course with 20% off! Highly recommending it!