
Squeeze #1: Distributed Training in Jupyter Notebooks
starting distributed training from notebook at ease w/ nbdistributed.


As I promised on linkedin. This is the first part of the Squeeze series. It is just me documenting what I am learning each week from Zachary Mueller's lightning talks and The Course.
It's going to be all about squeezing every last FLOP from our GPUs to the limits.
Let's first talk about why is the nbdistributed project would be useful. Whether you're on the recent genai or traditional ml side; many of us still goes to jupyter notebooks to prototype architectures or ml system that we're building. It can be like finetuning an llm, or building your first regression model to classify the signals that you have. Even though most of the experienced data practitioners transition to the python scripts (because eventually you need to do mlops) ; there are still huge part of the researchers and engineers that works on the notebooks. If you don't believe me, just ask to the Alec Radford
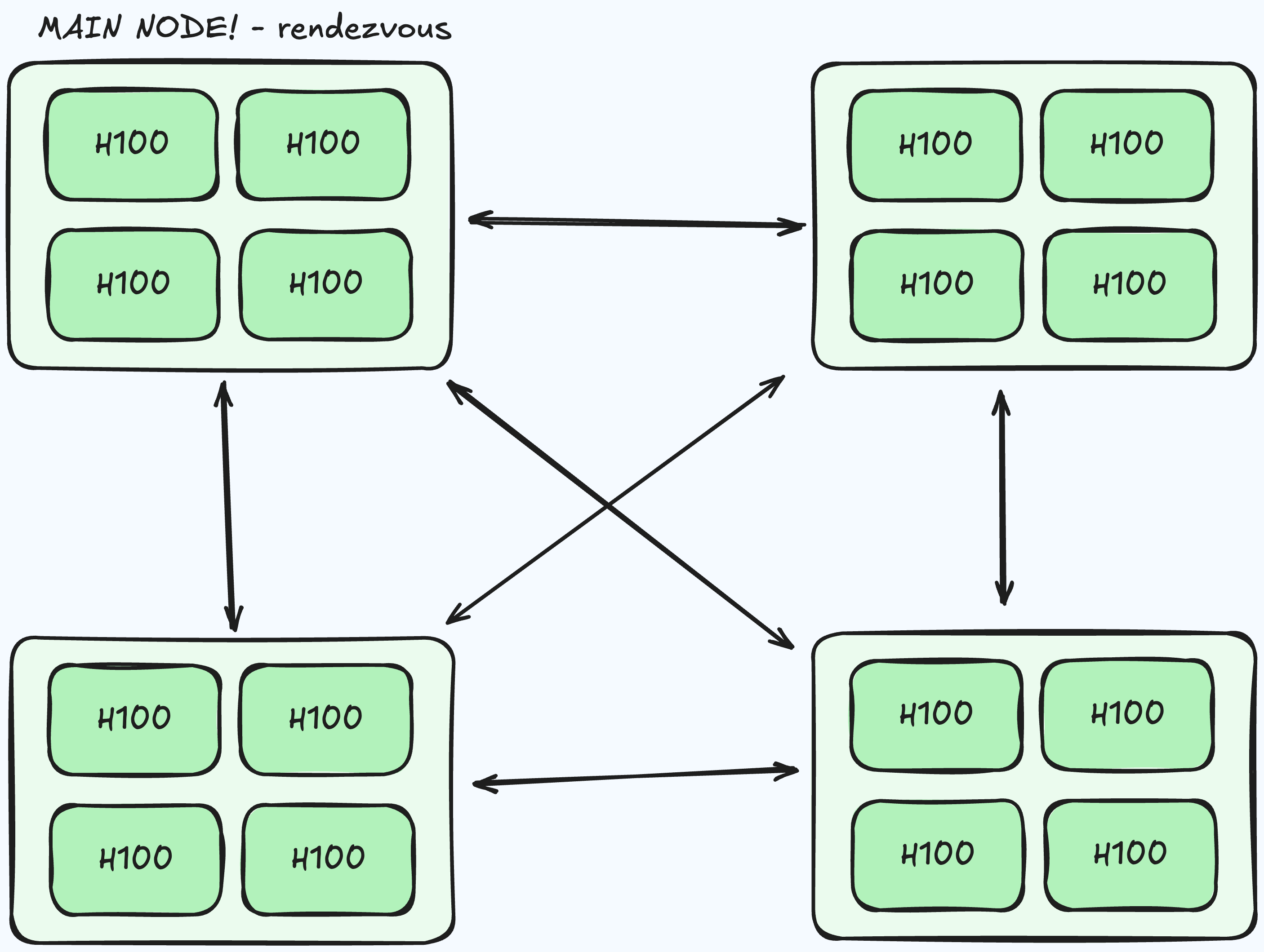
Yeah, but notebook environment is just a one python process, so it can only parallelize inside that machine. If you go to the multi-node setup, the whole thing just changes. You need to setup communication between the nodes → in my case it was accelerate doing it with main rank's ip and related port to communicate over. Means that to truly scale out you need to start separate processes on each node and direct them to a rendezvous IP/port for the main rank.
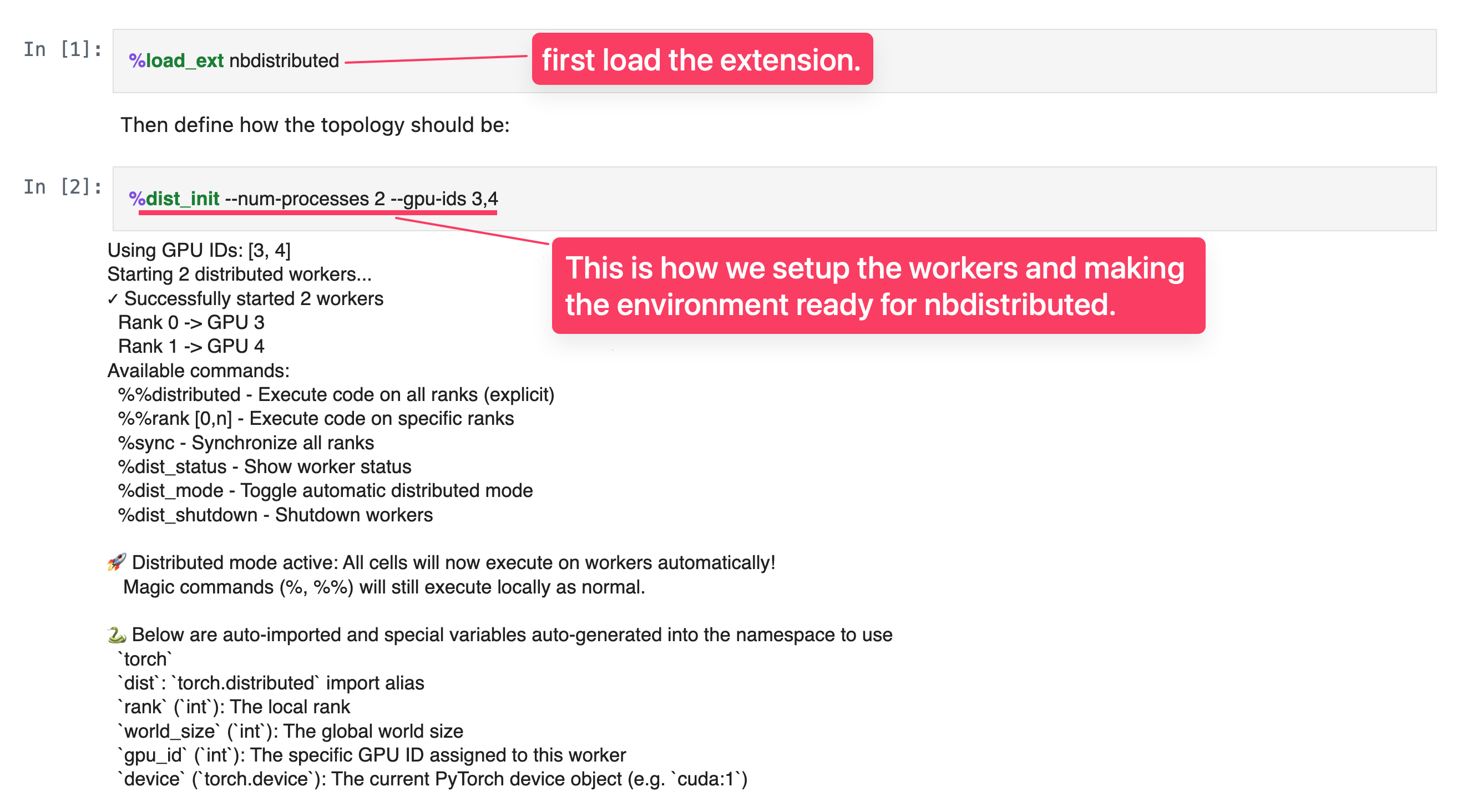
There's already an implementation for launching training from a notebook; and it's called notebook_launcher! I haven't personally used it yet, but if I wanted to launch a dist. training job from a notebook, that would be my go-to, and I bet most people's too.
But here's the thing, when you want to optimize your fine-tuning or training script, you don't need to try it out every time from python, you need to tinker, observe and try it out again and again. That's where nbdistributed stands out as a debugging tool. You can run code selectively on one rank, check it out variables for each rank etc. without re-running the whole thing!
Let me show you the capabilities and interactive environment with screenshots.
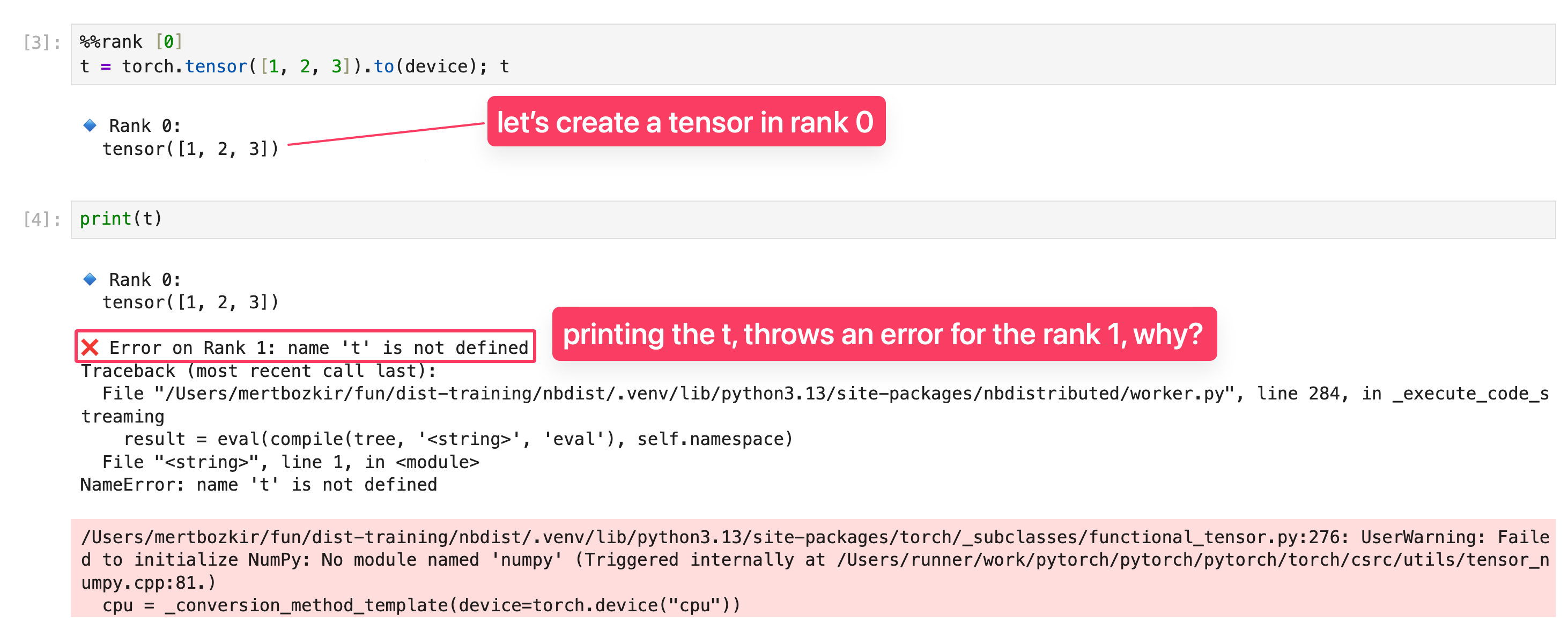
It throws an error, because we didn't create the tensor in rank 1. And the nbdistributed is works in this way;
if you don't specify the rank
it will run in the all ranks.
if you specify a rank, e.g: %%rank [0]
then it will only in that rank!

it's a really cool debugging tool. So if you want to learn more about this tool, please check it out this lightning talk.

To become up-to-date with the latest distributed training concepts. Use the following button to get Zach's course with 20% off! Highly recommending it!
Closing note: I've started posting on instagram. Check it out
Amazing! Need more of these